Computer Architecture and Organization (CT 211) - Exam
THE UNIVERSITY OF DODOMA
OFFICE OF THE DEPUTY VICE CHANCELLOR ACADEMIC, RESEARCH AND CONSULTANCY
COLLEGE OF INFORMATICS AND VIRTUAL EDUCATION
Department of Computer Science and Engineering
End of Semester One University Examination for the 2023/2024 Academic Year
Course Name: Computer Architecture and Organization
Paper Code Number: CT 211
Date of Examination: 28th February, 2024
Time: 08:00-11:00
Duration: 3 Hours
Venue(s): LRB 105, 004C, LRB 004D, 005B, 003D, 101, 102, LRB LRA 020, 101&102
Sitting Programme(s): BSc. SCDFE2, CE2, CNISE2, CS2, MTA2&SE2
SECTION A: (40 MARKS)
Answer all questions in this section
Question One
a. Explain the principle of locality and how it affects Caching Memory? (4 Marks)
Answer (Click to show)
Locality principle and how it affect caching memory Locality Principle: A program tends to access data that form a physical cluster in the memorybmultiple accesses may be made within the same block. There are two basic forms of locality:
Temporal locality - refers to the phenomenon that once a particular memory item has been referenced, it is most likely that it will be referenced next, for example, Recently accessed items tend to be accessed again in the near future.
Spatial locality - refers to the phenomenon that when a given address has been referenced, it is most likely that addresses near it will be referenced within a short period of time for example, consecutive instructions in a straight-line program such as Arrays.
Cache coherency Cache coherency is a computer system concept based on multiprocessor systems, that ensures that multiple processors have consistent access to shared data. When multiple processors share a common memory, they often use caches to store frequently accessed data. However, if these caches are not managed properly, inconsistencies can arise, leading to incorrect program execution. Importance of Cache coherency is Data Integrity, Correct program execution and Performances.
c. What happens when a new item needs to be added to cache but there is not enough space left? (2 Marks)
(Click to show)
When new items need to be added to cache memory and there is no enough space left (Lecture 4B, Slide 38)
Cache replacement policy is employed to determine which existing item should be evicted to make room for the new one. Some common cache replacement policies: FIFO (First In First Out), LRU (Least Recently Used), LFU (Least Frequently Used), Random Selection and LFU-SC (Least Frequently Used with Second Chance).
Cache hit: One field of the main memory address points us to a location in cache in which the data resides. While, Cache miss: where it is to be placed if it is not resident
Question Two
a. What causes divide underflow and what can be done about it? (4 Marks)
Answer (Click to show)
Divide underflow occurs when the result of a division operation is so small that it falls below the smallest representable number in the floating-point format being used. This can lead to unexpected results or errors in calculations. Below are the causes, consequences and prevention.
Causes: • Dividing a small number by a large number: When a very small number is divided by a much larger number, the result can be so tiny that it cannot be accurately represented in the floating-point format. • Repeated divisions: Performing multiple divisions in succession can gradually reduce the magnitude of the result, eventually leading to underflow. • Using a floating-point format with a limited range: Floating-point formats have a minimum exponent value, below which numbers cannot be represented. Dividing a number by a value that exceeds this limit can result in underflow.
Consequences: • Loss of precision: Underflow can lead to a loss of precision in calculations, as the significant digits of the result may become zero. • Incorrect results: Inaccurate calculations due to underflow can produce incorrect outputs or lead to unexpected behavior in programs. • Errors or exceptions: Some programming languages or libraries may raise errors or exceptions when underflow occurs, interrupting the execution of the program.
Prevention and Mitigation: • Check for underflow conditions: Before performing a division, check if the result is likely to underflow. This can be done by comparing the magnitudes of the dividend and divisor. • Scale values: If dealing with very small numbers, consider scaling them to a larger range to avoid underflow. This can be done by multiplying or dividing both the dividend and divisor by a suitable factor. • Use alternative data types: If underflow is a concern, consider using a data type with a wider range, such as a double instead of a float. • Handle underflow gracefully: If underflow cannot be avoided, handle it gracefully by providing default values, logging errors, or taking other appropriate actions.
b. Why do we usually store floating-point numbers in normalized form? What is the advantage of using a bias as opposed to adding a sign bit to the exponent? (6 Marks)
Answer (Click to show)
Normalization of Floating-Point Numbers Normalization is a standard representation for floating-point numbers that ensures a consistent format and simplifies arithmetic operations. In normalized form, the leading digit (excluding the sign bit) of the significand is always non-zero. This ensures that the maximum precision is used for the number, as there are no leading zeros that contribute no significant information.
Advantages of Normalization • Consistent Representation: All normalized numbers have a similar structure, making it easier for hardware and software to process them efficiently. • Simplified Arithmetic: Many floating-point operations, such as addition and multiplication, become simpler when numbers are normalized. • Efficient Comparison: Comparing normalized numbers is more straightforward as the leading digit is always non-zero. • Maximum Precision: Normalization ensures that the maximum possible precision is used for a given number, as there are no wasted bits.
Bias vs. Sign Bit for Exponent The exponent of a floating-point number represents the magnitude or scale of the number. To avoid negative exponents, which can be cumbersome for hardware implementation, a bias is often used. The bias is a constant value added to the actual exponent, making it always positive.
**Advantages of Using Bias: ** • Simplified Hardware: Using a bias allows for simpler hardware implementations of floating-point arithmetic, as there is no need to handle negative exponents directly. • Efficient Comparison: Comparing exponents becomes easier when they are always positive. • Consistent Representation: The bias ensures a consistent representation of exponents, making it easier to interpret and manipulate them.
In conclusion, normalization and the use of a bias for the exponent are essential features of floating-point representation. They provide a consistent, efficient, and precise format for representing real numbers in computers.
Question Three
a. List down four key characteristics of MARIE architecture. (4 Marks)
Answer (Click to show)
Four key characteristics of MARIE architecture
MARIE (Machine Architecture for Research and Instruction of Elementary) is a simplified model of a computer architecture designed for educational purposes. It provides a fundamental understanding of computer hardware and software principles. Here are four key characteristics of MARIE architecture:
i. Single-Address Instruction Format: Each MARIE instruction consists of an opcode (operation code) and an address field. The opcode specifies the operation to be performed, and the address field indicates the memory location of the operand. This simple format makes it easier to understand and implement basic machine instructions.
ii. Limited Instruction Set: MARIE has a limited set of instructions, focusing on fundamental operations such as loading, storing, arithmetic, and branching. This simplified instruction set makes it easier to learn and understand the basics of computer programming and assembly language.
iii. Small Memory: MARIE typically has a small memory size, often limited to a few hundred words. This helps to focus on the essential concepts of memory addressing and organization without getting overwhelmed by large memory spaces.
iv. Simplified Input/Output: MARIE’s input/output capabilities are often limited to basic operations such as reading from and writing to a single input/output device. This simplifies the understanding of input/output operations and their interaction with the processor.
These characteristics make MARIE an ideal platform for learning the fundamental concepts of computer architecture, assembly language programming, and the relationship between hardware and software.
b. Describe in brief essential components in MARIE data Path, with the aid of a well labelled diagram. (6 Marks)
Answer (Click to show)
Essential components in MARIE data path, with the aid of well labeled diagram
Components: i. Memory: Stores instructions and data. ii. Program Counter (PC): Holds the address of the next instruction to be executed. iii. Instruction Register (IR): Stores the current instruction being executed. iv. Accumulator (AC): A general-purpose register used to hold intermediate results of arithmetic operations.5. MAR (Memory Address Register): Holds the address of the memory location to be accessed. v. MDR (Memory Data Register): Holds the data to be read from or written to memory. vi. Control Unit (CU): Decodes instructions and controls the flow of data between the components. vii. Input/Output (I/O) Devices: Allow the computer to interact with the external world.
Diagram:
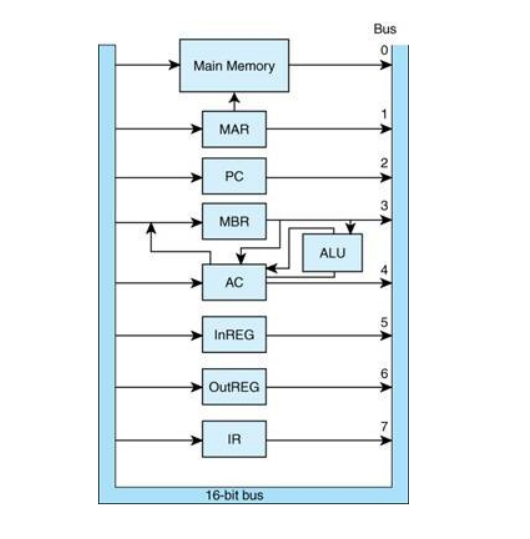
Question Four
Assume you have a machine that uses 32-bit integers and you are storing the hexadecimal value 1234 at address 0.
i. Show how this is stored on a big endian machine. (2 Marks)
Answer (Click to show)
Big Endian machine

ii. Show how this is stored on a little endian machine. (2 Marks)
Answer (Click to show)
Little Endian machine

iii. If you wanted to increase the hexadecimal value to 123456, which byte assignment would be more efficient, big or little endian? Explain your answer. (6 Marks)
Answer (Click to show)
Little endian byte assignment would be more efficient because Most UNIX machines are big endian, whereas most PCs are little endian machines. Most newer RISC architectures are also big endian. And If a programmer writes an instruction to read a value of the wrong word size, on a big endian machine it is always read as an incorrect value; on a little endian machine, it can sometimes result in the correct data being read.

SECTION B: (60 MARKS)
Attempt any THREE (3) out of FOUR (4) questions provided.
Question Five
a. Explain the advantages and disadvantages of each of following processor implementations: (3 Marks Each)
i. Single-cycle implementation.
Answer (Click to show)
Advantages: • Simple design: Easy to understand and implement. • Regular structure: The control logic is relatively straightforward. • Short design time: Can be developed quickly.
Disadvantages: • Slow performance: Each instruction takes a fixed number of clock cycles to complete, regardless of its complexity. • Inefficient use of resources: Some resources may be underutilized for simple instruction
ii. Multiple-cycle implementation.
Answer (Click to show)
Multiple-Cycle Implementations
Advantages: • Improved performance: Can execute simple instructions in fewer clock cycles than a single-cycle implementation. • Better resource utilization: Can optimize the use of resources for different types of instructions.
Disadvantages: • More complex design: Requires more complex control logic to handle different instruction execution times. • Increased design time: Can take longer to develop due to the increased complexity.
iii. Pipelined implementation.
Answer (Click to show)
Pipelined Implementations
Advantages: • High performance: Can execute multiple instructions simultaneously, increasing throughput. • Reduced average instruction time: Can improve overall performance, even if individual instructions take longer to execute. • Efficient resource utilization: Can better utilize hardware resources by overlapping the execution of different stages of the instruction cycle.
Disadvantages: • Increased complexity: Requires more complex control logic and hardware to manage the pipeline. • Potential for hazards: Can be susceptible to hazards (data, control, structural) that can reduce performance. • Increased design time: Can take longer to develop due to the increased complexit
b. With the aid of well-labeled diagram, draw the single-cycle data-path for each of the following instructions stating clearly the hardware used.
i. Load and store instructions. (6 Marks)
ii. ALU instruction. (5 Marks)
Question Six
a. Suppose a computer using set associative cache has 2²¹ words of main memory, and a cache of 64 blocks, where each cache block contains 4 words.
i. If this cache is 2-way set associative, what is the format of a memory address as seen by the cache, i.e., what are the sizes of the tag, set, and word fields? (5 Marks)
ii. If this cache is 4-way set associative, what is the format of a memory address as seen by the cache? (5 Marks)
b. Suppose a computer using direct mapped cache has 2³² words of main memory, and a cache of 1024 blocks, where each cache block contains 32 words.
i. How many blocks of main memory are there? (2 Marks)
ii. What is the format of a memory address as seen by the cache, i.e., what are the sizes of the tag, block, and word fields? (6 Marks)
iii. To which cache block will the memory reference 000063FA₁₆ map? (2 Marks)
Question Seven
a. What are pipeline hazards? (2 Marks)
Answer (Click to show)
Pipeline hazards are factors that contribute to delaying or prevention of instruction execution due to instruction conflicts including data dependencies, resource conflicts and fetch access delay from memory.
b. Briefly explain the following classes of pipeline hazards:
i. Data hazard. (3 Marks)
Answer (Click to show)
Data hazards Data hazards occur when an instruction depends on the result of a previous instruction that is still in the pipeline. This can lead to a stall or a wrong result if the data is not available when needed.
Examples of data hazards: • Read-after-write (RAW): An instruction tries to read a value from a register before the previous instruction that writes to that register has completed. • Write-after-read (WAR): An instruction tries to write a value to a register before the previous instruction that reads from that register has completed. • Write-after-write (WAW): Two instructions try to write to the same register.
Mitigation: (Techniques to reduce or control) • Forwarding: Pass the result of an instruction directly to the next instruction that needs it, bypassing the register file. • Stalling: Pause the pipeline until the required data becomes available. • Reordering: Rearrange instructions to avoid data hazards.
ii. Control hazard. (3 Marks)
Answer (Click to show)
Control hazards Control hazards occur when the flow of control of the program is changed unexpectedly, such as when a branch instruction is taken or an exception occurs. This can disrupt the pipeline and cause instructions that should not have been executed to be executed.
Examples of control hazards: • A branch instruction is taken, and the pipeline needs to fetch the target instruction. • An exception occurs, and the pipeline needs to handle the exception.
Mitigation: (Techniques to reduce or control) • Branch prediction: Predict whether a branch will be taken or not and fetch the target instruction speculatively.• Delayed branches: Insert NOP (no-operation) instructions after a branch to allow time for the pipeline to flush. • Branch target buffers: Store the target address of frequently taken branches to reduce branch prediction misses.
Pipeline stall, also known as a pipeline bubble, is a situation where the execution of instructions in a pipeline is paused due to a hazard.
iii. Structural hazard. (3 Marks)
Answer (Click to show)
Structural hazards Structural hazards arise when multiple instructions require the same hardware resource at the same time. This can happen, for example, when two instructions both need to access the same memory location or use the same functional unit.
Examples of structural hazards: • Two instructions both require the same ALU (Arithmetic Logic Unit) for their execution. • Two instructions both need to access the same register file.
Mitigation: (Techniques to reduce or control) • Multiple functional units: Provide multiple units for each type of operation (e.g., multiple ALUs, multipliers). • Interleaving: Schedule instructions to avoid conflicts.
c. Briefly explain the techniques used to deal with Data and Control hazards. (5 Marks)
Answer (Click to show)
Explained in the above questions
d. Mention and explain briefly four (4) techniques for dealing with pipeline stalls caused by branch delay in pipelined processor implementation. (4 Marks)
Answer (Click to show)
Techniques used to deal with pipeline stalls caused by delay in pipeline processorimplementations
i. Forwarding • Data forwarding: Pass the result of an instruction directly to the next instruction that needs it, bypassing the register file. This helps to reduce the delay caused by data hazards.
ii. Stalling • Pipeline stall: Temporarily pause the pipeline until the required data or resource becomes available. This is a simple but effective technique to prevent incorrect execution.
iii. Reordering • Instruction reordering: Rearrange the instruction sequence to avoid hazards. This can be done statically at compile time or dynamically at runtime.
iv. Branch Prediction • Branch prediction: Predict whether a branch instruction will be taken or not. This allows the processor to fetch the target instruction speculatively, reducing the delay caused by control hazards.
v. Delayed Branches • Delayed branches: Insert NOP (no-operation) instructions after a branch instruction to allow time for the pipeline to flush and fetch the target instruction.
vi. Branch Target Buffers • Branch target buffers: Store the target address of frequently taken branches to reduce branch prediction misses.
vii. Speculative Execution • Speculative execution: Execute instructions before their dependencies are resolved, assuming that the branch predictions are correct. If a prediction is incorrect, the results of the speculative execution are discarded.
viii. Superscalar Execution • Superscalar execution: Execute multiple instructions in parallel, provided they are independent of each other. This can help to hide the effects of stalls by keeping the pipeline full. i
x. Out-of-Order Execution • Out-of-order execution: Allow instructions to be executed in a different order than they appear in the program, as long as the dependencies are respected. This can help to hide stalls and improve performance.
Question Eight
a. What are the main functions of the CPU? (4 Marks)
Answer (Click to show)
The central processing unit (CPU) is responsible for fetching program instructions, decoding each instruction that is fetched, and performing the indicated sequence of operations on the correct data.
Main functions of CPU • Fetching: retrieves instructions from memory and stores them in the instruction register.
• Decoding: decodes the instruction to determine the operation to be performed and the operands involved.
• Executing: carries out the operation specified by the instruction. This may involve performing arithmetic operations, logical operations, or data transfers.
• Storing: stores the results of the operation in memory or a register.
• Controlling: controls the flow of data between the various components of the computer, such as the memory, input/output devices, and other peripherals.
b. Explain what the CPU should do when an interrupt occurs. Include in your answer the method the CPU uses to detect an interrupt, how it is handled and what happens when the interrupt has been serviced. (4 Marks)
Answer (Click to show)
CPU Interrupts CPU interrupts are mechanisms used to signal the CPU that an event has occurred that requires immediate attention. This allows the CPU to respond to external events and handle unexpected situations without disrupting its normal execution flow.
Types of Interrupts: • Hardware Interrupts: Generated by external devices such as I/O devices (keyboard, mouse, disk), timers, or external interrupts.
• Software Interrupts: Generated by software instructions within the CPU itself, often used for debugging or system calls.
• Exceptions: A type of software interrupt that occurs when an error or unexpected condition arises during program execution, such as a divide-by-zero or memory access violation.
Interrupt Handling Process: i. Interrupt Detection: The CPU detects the interrupt signal.
ii. Interrupt Acknowledgement: The CPU acknowledges the interrupt, indicating that it will handle the event.
iii. Interrupt Vectoring: The CPU determines the appropriate interrupt handler routine based on the interrupt’s source.
iv. Context Switching: The CPU saves the current state of the program (e.g., registers, program counter) to be restored later.
v. Interrupt Handler Execution: The CPU executes the interrupt handler routine to address the event that triggered the interrupt.
vi. Context Restoration: The CPU restores the saved context and resumes the interrupted program.
Importance of Interrupts: • Responsiveness: Interrupts allow the CPU to respond quickly to external events, ensuring that the system remains responsive.
• Efficiency: Interrupts provide a mechanism for handling asynchronous events without requiring the CPU to constantly poll devices for changes.
• Flexibility: Interrupts can be used to implement a variety of system functions, such as I/O operations, multitasking, and error handling.
Example: When a user presses a key on the keyboard, a hardware interrupt is generated. The CPU responds by saving its current state, executing the keyboard interrupt handler, reading the key code, and updating the keyboard buffer. Once the interrupt is handled, the CPU restores its previous state and resumes execution.
c. Assume a 2²⁰ byte memory: (4 Marks Each)
i. What are the lowest and highest addresses if memory is byte-addressable?
ii. What are the lowest and highest addresses if memory is word-addressable, assuming a 16-bit word?
iii. What are the lowest and highest addresses if memory is word-addressable, assuming a 32-bit word?
END OF EXAMINATION PAPER